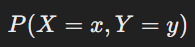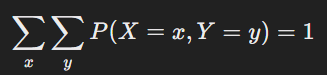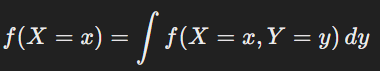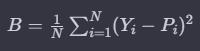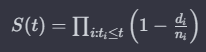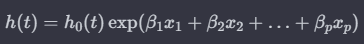통계적 가설 검정이란 데이터를 사용하여 어떠한 주장이나 가설이 옳은지를 결정하는 과정을 통계적인 방법을 통해 수행하는 것을 뜻한다. 여기서 두 가지의 키워드가 중요하다.
모집단: 통계적인 분석이나 추론의 대상이 되는 전체 집단. 연구자가 알고 싶어하는 대상
표본: 모집단의 부분집합. 연구자가 측정 또는 관찰한 결과들의 집합
즉, 가설 검정을 한다는 것은 연구자가 관찰한 표본들에 대하여 특정 통계 방법을 사용하여 모집단의 특성을 추론하고 일반화하는 과정이다. 연구자가 세운 가설에 대하여 데이터를 바탕으로 수치적인 근거를 제시하는 과정이기 때문에 데이터 분석 업무에서 중요한 요소라고 할 수 있다.
2. 가설 검정 절차
가설 검정: 귀무가설과 대립가설 설정
귀무가설: 일반적으로 어떤 변화나 효과가 없다는 것을 주장
대립가설: 귀무가설을 기각하고자 하는 주장
검정 통계량 선정
표본 데이터를 사용하여 가설 검정을 수행하는데 사용되는 통계량. 선택된 가설 검정 방법과 관련이 있음
가설 검정 방법
t-검정 통계량: 두 집단 간의 평균 차이 비교. 두 집단의 표본 평균과 표준 편차를 사용하여 계산
z-검정 통계량: 모집단의 평균이나 비율에 대한 가설 검정. 표준 정규 분포의 특정 점수를 계산하여 비교
F-검정 통계량: 두 개 이상의 집단의 분산 차이 비교. 주로 분산 분석 (ANOVA)에서 사용되며 집단 간 및 집단 내 분산 비교
카이제곱 통계량: 두 범주형 변수 간의 관계 검정. 관찰된 빈도와 기대된 빈도 사이의 차이 측정
특정 문제 또는 가설에 따라 다양한 검정 통계량이 사용되며, 더 자세한 내용은 관련 포스트를 통해 다룰 예정이다.
유의수준 설정
유의수준: 귀무가설을 기각하기 위한 임계값. 일반적으로 사용되는 유의수준은 0.05 또는 0.01
행과 행간의 관계를 쉽게 정의하기 위해 만든 함수를 뜻함. 집계함수를 사용한다는 점에서 groupby 집계와 비슷하지만 윈도우 함수와 큰 차이점이 존재한다. 바로 출력되는 데이터 형태의 '집약' 여부다. 직관적인 차이는 아래 예시와 같다.
-- GROUP BY절을 이용한 집계
SELECT
category
,COUNT(name) as category_cnt
FROM tutorial.animal_crossing_construction
GROUP BY category
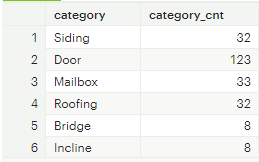
[그림 1] group by 집계 결과
-- Window 함수를 이용한 집계
SELECT
category
,COUNT(name) OVER (PARTITION BY category) as category_cnt
FROM tutorial.animal_crossing_construction
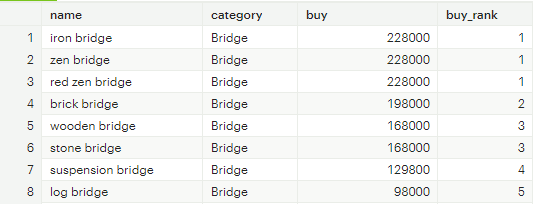
[그림2] window 함수 집계 결과
위의 예시는 Mode SQL 사이트에서 animal_crossing_construction 이라는 튜토리얼 테이블로 실행한 결과다. 두 쿼리 결과를 비교해 보았을 때,
groupby 절은 집계하고자 하는 속성의 고유 개수만큼 결과가 집약되어 출력
window 함수는 집계하고자 하는 속성의 고유 개수에 관계 없이 모든 행에 집계 결과를 출력
와 같은 차이점을 보이고 있다.
2. 집계 함수
2.1) 순위 함수
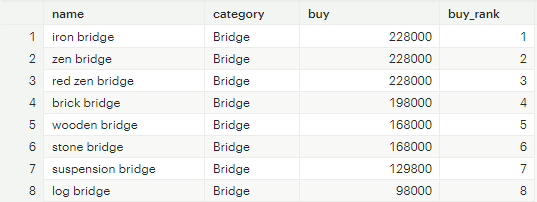
RANK: 특정 컬럼의 순위 도출하는 함수. 동일한 값에 대해서는 같은 순위를 부여하며 중간 순위는 비움.
-- RANK 함수를 이용한 집계
SELECT
name
,category
,buy
,RANK() OVER (PARTITION BY category ORDER BY buy DESC) as buy_rank
FROM tutorial.animal_crossing_construction
[그림 3] RANK 함수 쿼리 결과
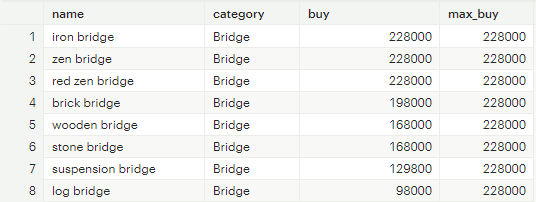
DENSE_RANK: 동일한 값에 대해서 같은 순위를 부여. RANK함수와 달리 중간 순위를 비우지 않음
-- DENSE_RANK 함수를 이용한 집계
SELECT
name
,category
,buy
,DENSE_RANK() OVER (PARTITION BY category ORDER BY buy DESC) as buy_rank
FROM tutorial.animal_crossing_construction
[그림 4] DENSE_RANK 함수 집계 결과
ROW_NUMBER: RANK, DENSE_RANK 함수와 달리 동일한 값에도 고유 순위를 부여함.
-- ROW_NUMBER 함수를 이용한 집계
SELECT
name
,category
,buy
,ROW_NUMBER() OVER (PARTITION BY category ORDER BY buy DESC) as buy_rank
FROM tutorial.animal_crossing_construction
[그림 5] ROW_NUMBER 함수 집계 결과
2.2) 일반 집계 함수
SUM: 합계
MAX: 최대값
MIN: 최소값
AVG: 평균값
COUNT: 개수
-- MAX 함수를 이용한 집계
SELECT
name
,category
,buy
,MAX(buy) OVER (PARTITION BY category ORDER BY buy DESC) as max_buy
FROM tutorial.animal_crossing_construction
[그림 6] MAX 함수 집계 결과
일반 집계 함수는 순위 함수와 달리 () 안에 집계하고자 하는 대상의 컬럼명을 기입해야 함.
2.3) 그룹 내 행 순서 함수
FIRST_VALUE: over 절 내 partition 별 윈도우에서 가장 먼저 나온 값 도출
-- FIRST_VALUE 함수를 이용한 집계
SELECT
name
,category
,buy
,FIRST_VALUE(buy) OVER (PARTITION BY category) as first_buy
FROM tutorial.animal_crossing_construction
[그림 7] FIRST_VALUE 함수 집계 결과
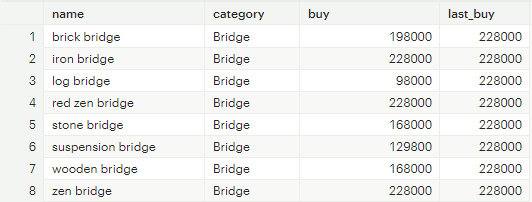
LAST_VALUE: over 절 내 partition 별 윈도우에서 가장 나중에 나온 값 도출
-- LAST_VALUE 함수를 이용한 집계
SELECT
name
,category
,buy
,LAST_VALUE(buy) OVER (PARTITION BY category) as last_buy
FROM tutorial.animal_crossing_construction
[그림 8] LAST_VALUE 함수 집계 결과
LAG: 이전 n번째 행의 값 가져옴. 최대 3개의 인자를 가지며
첫 번째 인자: 집계할 컬럼명
두 번째 인자: 몇 번째 앞의 행을 가져올지 결정 (default 값은 1)
세 번째 인자: 가져올 행이 없을 경우 채우고자 하는 값
-- LAG 함수를 이용한 집계
SELECT
name
,category
,buy
,LAG(buy, 2) OVER (PARTITION BY category) as lag_buy
FROM tutorial.animal_crossing_construction
[그림 9] LAG 함수 이전 2번째 값 집계 결과
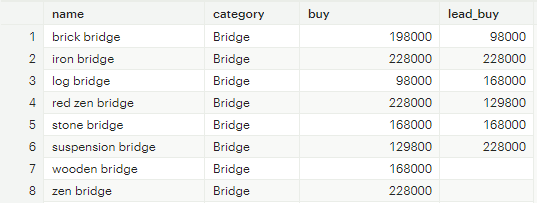
LEAD: 이후 n번째 행의 값 가져옴. 인자 개수는 LAG 함수와 동일
-- LEAD 함수를 이용한 집계
SELECT
name
,category
,buy
,LEAD(buy, 2) OVER (PARTITION BY category) as lead_buy
FROM tutorial.animal_crossing_construction
[그림 10] LEAD 함수 이후 2번째 값 집계 결과
2.4) 그룹 내 비율 함수
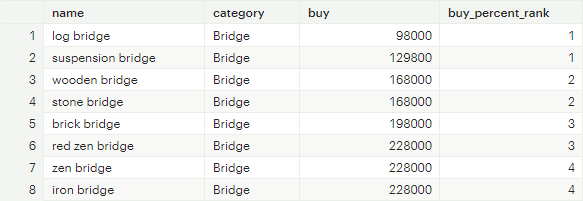
PERCENT_RANK: partition 별로 가장 먼저 나오는 값을 0, 마지막에 나오는 값을 1로 해서 순서별 백분율 산출
-- PERCENT_RANK 함수를 이용한 집계
SELECT
name
,category
,buy
,PERCENT_RANK() OVER (PARTITION BY category ORDER BY buy) as buy_percent_rank
FROM tutorial.animal_crossing_construction
[그림 11] PERCENT_RANK 함수 집계 결과
CUME_DIST: partition 별 누적백분율 산출
-- CUME_DIST 함수를 이용한 집계
SELECT
name
,category
,buy
,CUME_DIST() OVER (PARTITION BY category ORDER BY buy) as buy_percent_rank
FROM tutorial.animal_crossing_construction
[그림 12] CUME_DIST 함수 집계 결과
NTILE: partition 별 집계 결과를 n등분한 결과 산출. 이 때, 해당 함수의 인자로 몇 등분할 것인지 숫자를 지정해야 함.
-- NTILE 함수를 이용한 집계
SELECT
name
,category
,buy
,NTILE(4) OVER (PARTITION BY category ORDER BY buy) as buy_percent_rank
FROM tutorial.animal_crossing_construction
[그림 13] NTILE 함수 4등분 집계 결과
3. Window Function 구문
[그림 14] Window Function 문법 (참고링크: https://cloud.google.com/bigquery/docs/reference/standard-sql/window-function-calls)
상단의 이미지는 Window 함수 문법구조를 나타내고 있다. Google Cloud 내 Bigquery 가이드 문서에서 참고한 내용이다.
Window 함수의 대략적인 구조는 다음과 같다.
function_name: 윈도우 절을 동작시키는 집계함수를 뜻함. 앞서 소개한 집계함수들이 모두 이에 해당됨. 여기서 argument_list는 집계함수의 특성에 따라 들어갈 수도 있고 안들어갈 수도 있음.
OVER: 윈도우 함수를 사용함을 나타내는 키워드로 반드시 기입해야 함.
over_clause: function_name (집계함수)을 어떻게 주어진 행에 적용시킬지 나타내는 구문. () 안에 조건을 기입함.
PARTITION BY: 윈도우 함수를 어떤 컬럼 카테고리를 기준으로 나눌지 설정하는 구문. group by 와 비슷한 역할을 한다고 생각하면 됨.
ORDER BY: 윈도우 함수를 어떤 컬럼을 기준으로 정렬할지 설정하는 구문. 오름차순이면 ASC 또는 빈 구문, 내림차순이면 DESC를 기입
window_frame_clause: 윈도우 함수에 적용되는 행을 어떤 범위로 구간을 나눌지 적용시키는 구문
rows_range
ROWS: 물리적 행 단위. 모든 행을 1개의 행으로 독립적으로 인식
RANGE: 논리적 행 집합. ORDER BY절에 명시된 컬럼으로 논리적인 행 집합 구성. 집합으로 묶인 그룹이 1개의 행으로 인식됨.
frame_start | frame_between
CURRENT ROW: 현재 행
UNBOUNDED:가장 맨 앞 또는 맨 뒤의 행
(UNBOUNDED OR N) PRECEDING: 이전 N번째 행
(UNBOUNDED OR N) FOLLOWING: 다음 N번째 행
rows_range와 frame_start | frame_between 구문의 종류 별 예시를 통해 차이를 알아보자.
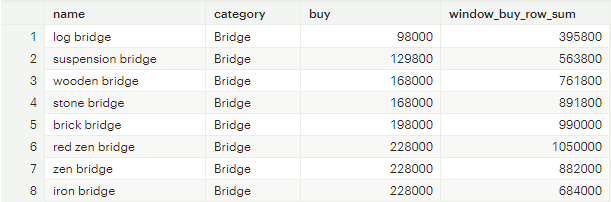
1. ROWS와 RANGE의 차이
SELECT
name
,category
,buy
,SUM(buy) OVER (PARTITION BY category ORDER BY buy ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as window_buy_row_sum
,SUM(buy) OVER (PARTITION BY category ORDER BY buy RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as window_buy_range_sum
FROM tutorial.animal_crossing_construction
[그림 15] ROWS와 RANGE의 차이
sum() 집계 함수를 사용하여 category 컬럼의 속성 별로 나누어 (partition by) buy 컬럼을 기준으로 오름차순 (order by) 할 때, 첫 번째 행부터 헌재 행 (BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)까지 집계하는 window 함수를 명시한 결과다.
ROWS: 각 행을 독립적인 행으로 간주. 현재 행으로부터 이전 행의 모든 buy컬럼 값을 합산하여 누적 합을 계산
RANGE: order by 절에 명시했던 buy컬럼의 값을 기준으로 행을 묶어서 집계. 즉, buy 컬럼의 속성 값이 동일할 경우, 동일한 행으로 간주하고 합계를 계산
2. PRECEDING & FOLLOWING
SELECT
name
,category
,buy
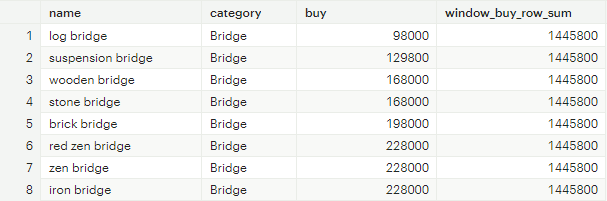
,SUM(buy) OVER (PARTITION BY category ORDER BY buy ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING) as window_buy_row_sum
FROM tutorial.animal_crossing_construction
[그림 16] PRECEDING & FOLLOWING 예시
category 컬럼의 각 카테고리 속성 내에서 현재 행 기준으로 이전 2개, 이후 2개에 해당되는 buy값을 합계한 결과다.
3. UNBOUNDED
SELECT
name
,category
,buy
,SUM(buy) OVER (PARTITION BY category ORDER BY buy ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as window_buy_row_sum
FROM tutorial.animal_crossing_construction
[그림 17] UNBOUNDED 예시
category 컬럼의 각 카테고리 속성 내에서 현재 행 기준으로 이전 모든 행, 이후 모든 행에 해당되는 buy값을 합계한 결과다.
Non-parametric: 데이터의 독립 변수와 생존 시간 분포를 모두 사용하지 않는 방법. 분포 정보를 알 수 없을 때 유용하지만 예측이 부정확 할 수 있음 (Ex. Kaplan-Meier)
Semi-parametric: 데이터의 독립 변수는 사용, 생존 시간 분포 정보는 사용하지 않는 방법. (Ex. Cox 비례 위험 모형)
Parametric: 생존 시간 분포가 존재한다고 가정하고 회귀 모델로 생존 시간을 예측. (Ex. 지수 분포, 로지스틱 분포, Weibull 분포)
Machine Learning: 머신러닝 알고리즘을 생존 분석에 적용한 기법. 비선형 관계에 있는 독립 변수를 사용하여 모델링이 가능함
그림1에 나와있듯, 다양한 생존분석 방법론들이 존재하나, 여기서는 Machine Learning을 활용한 분석 방법에서 SVM과 앙상블 기법에 대해 자세히 다뤄볼 예정이다.
2. 머신러닝 방법론
2.1) Survival SVM (Support Vector Machine)
SVM은 데이터에 존재하는 클래스 간의 경계를 찾는 지도학습 알고리즘이다. 클래스를 나누는 결정 경계는 클래스 간의 간격 (마진)을 최대화하는 것이 목표라고 할 수 있다. SVM에 대한 자세한 설명은 머신러닝 챕터에서 소개할 예정이고 주요 개념만 써보겠다.
<SVM 주요 개념>
결정 경계: 주어진 데이터를 나누는 역할. 클래스 간의 간격 (마진)을 최대화하는 것이 목표 (보통의 그림에는 x, y 축에는 주어진 데이터의 변수들이 들어간다고 이해할 수 있음)
서포트 벡터: 결정 경계에 가장 가까이 있는 데이터 포인트. 결정 경계의 모양 결정하는데 주요 역할
커널 트릭: 데이터를 고차원으로 매핑하여 비선형 결정 경계 탐색 (Ex. Radial Basis Function Kernel)
마진: 결정 경계와 서포트 벡터 사이의 거리. 이 마진을 최대화할수록 좋은 성능가진 SVM이라고 할 수 있음
하드 마진: 데이터가 완벽하게 선형적으로 나누어진 경우, 이상치에 민감
소프트 마진: 일부 오차 허용하여 일반화 성능을 향상
Survival SVM은 크게 두 가지 접근법으로 사용될 수 있다. 주어진 데이터의 독립변수들을 이용하여,
순위 문제: 주어진 데이터의 모든 샘플 쌍을 고려하여 생존 시간이 더 짧은 샘플을 더 낮은 순위로 할당 (샘플 aka 데이터 포인트), 해당 샘플이 순위가 낮을수록 이벤트가 발생할 가능성 (발생 위험도)이 높다고 가정
장점: 이벤트가 드물게 발생하는 경우에도 상대적인 순위 기반으로 학습 가능
단점
해석의 어려움: 특정 순위 부여한 이유를 명확히 알기 어려움
제한된 정보: 명확한 생존 확률 또는 시간 정보가 제공되지 않고 각 샘플 간의 상대적인 순위만 나오므로 해석이 모호함.
회귀 문제: 주어진 데이터들의 생존 시간을 직접 예측
장점
해석 용이: 각 독립 변수의 회귀 계수를 통해 각 변수의 영향도 추정 가능
기존 회귀 모델과의 비교 용이함
단점
이벤트 적은 경우, 적절한 예측 수행이 어려움 (데이터 이벤트 발생 여부 클래스 불균형 발생)
제약된 선형 가정: 회귀 예측 특성 상, 독립 변수와 종속 변수 간의 선형 관계를 가정. 생존 데이터의 특성 상 부합하지 않을 수도 있음
2.2) Ensemble Learning
[그림 2] Ensemble 기법 종류
그림 2에 나와있듯, 앙상블 기법에는 부스팅, 배깅, 스태킹 총 3가지의 알고리즘이 있다.
부스팅: 일련의 모델이 순차적으로 학습되며 각 모델은 이전 모델의 오류를 수정, 잘못 분류된 샘플의 가중치를 증가시켜 다음 모델에서 개선시키는 알고리즘 (Ex. AdaBoost)
배깅: 훈련 데이터를 무작위 중복 허용하여 하위 집합을 만든 후 (bootstrap sampling), 독립적으로 동일한 모델을 학습. 이 때, 회귀 모델의 경우 각 모델 예측 값 평균, 분류일 경우 다수결 투표 등을 통해 최종 예측 결정 (Ex. Random Forest)
스태킹: 훈련 데이터에 대하여 서로 다른 모델을 훈련시킨 후, 각 모델들의 예측 결과를 새로운 변수로 사용하여 메타 모델을 학습. 메타 모델은 각 모델들의 예측을 바탕으로 최종 예측 수행
2.2.1) Random Survival Forest
Random Survival Forest는 기존 Random Forest 모델에서 생존 분석에 맞게 변형한 모델이다.
간략한 동작 순서는
Bootstrap Sampling: Bootstrap 샘플링을 통해 무작위로 선택된 데이터로 구성하여 트리를 생성
무작위 독립 변수 선택: 무작위로 선택된 독립 변수를 사용하여 트리를 분할
이벤트 트리 구성: 이벤트 트리는 각 노드에서 특정 시간 구간에 이벤트가 발생할 확률을 계산
생존 함수 예측: 각 트리의 이벤트 트리를 통해 개별 관측치에 대한 생존 함수 예측. 모든 트리에서의 예측을 종합하여 최종적인 생존 함수 형성 (생존 함수: 주어진 시간에 대해 이벤트가 발생하지 않을 확률)
최종적으로 생성된 생존 함수를 통해 Random Survival Forest에서는 위험도를 추정할 수 있다.
2.3) 성능 지표
2.3.1) Concordance Index (C-index)
단순히 예측시간에 대한 정확도만 보고싶을 경우에는 MSE와 같은 지표를 사용해도 되지만, 이벤트 발생 여부에 대한 것도 같이 고려하기 위해서는 다른 성능지표가 필요하다.
C-index는 이벤트가 발생하기까지 걸리는 시간과 함께 이벤트 발생 여부도 같이 고려한다는 점에서 생존 분석에서 자주 사용되는 성능 지표다.
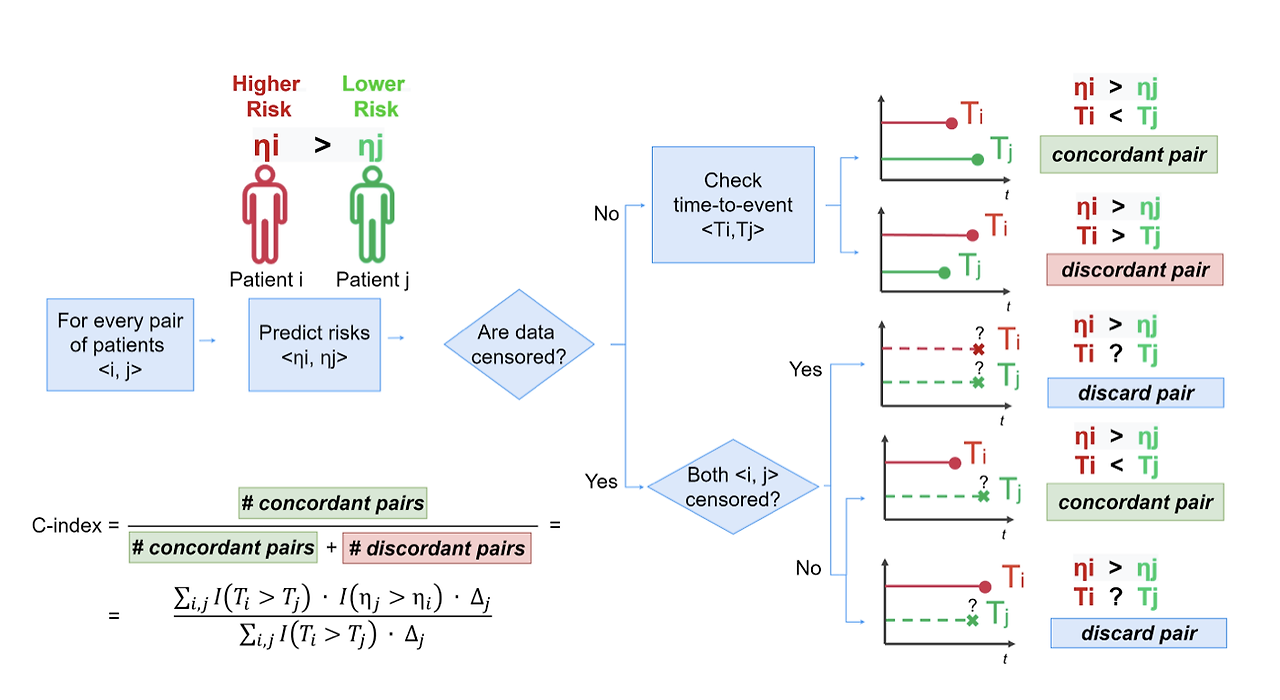
[그림 3] C-index 평가 방식
C-index에서는 두 관측치 간의 비교를 통해 모델의 성능을 평가한다. 두 관측치를 쌍 (A, B)으로 구성하는데,
관측치 A가 관측치 B보다 위험도가 더 높게 예측된 경우, 관측치 A의 생존 시간이 관측치 B보다 생존시간이 짧을 경우
관측치 A가 관측치 B보다 위험도가 더 낮게 예측된 경우, 관측치 A의 생존 시간이 관측치 B보다 생존시간이 길 경우
올바르게 예측했다고 간주하고 성능 지표를 계산한다. (그림 3의 concordant pair)
반대의 경우에는 틀리게 예측했다고 계산한다. (그림 3의 discordant pair)
다만, 두 관측치가 모두 중도절단되거나 한 관측치가 이벤트 발생한 시점보다 더 일찍 중도절단되었을 경우 계산에 포함되지 않는다. (그림 3의 discard pair)
C-index는 0~1 사이의 값을 갖게 되며, 1에 가까울수록 모델의 성능이 좋다고 해석된다. 0.5에 가까울수록 무작위로 예측했다고 해석할 수 있다.
2.3.2) Brier Score
Brier Score는 모델의 생존 예측 확률과 실제 이벤트 발생 여부 간의 평균 제곱 차이를 측정하는 지표다.
Brier Score 수식
N: 관측치 수
Y(i): i번째 관측치의 실제 이벤트 발생 여부를 나타내는 이진 변수 (이벤트 발생 시 1, 아니면 0)
직역하면 인과 영향이라는 뜻이다. 처음에는 Causal Inference (인과 추론)과 개념이 혼동되어서 햇깔리는 부분이 있었다. Inference와 Impact가 어떤 차이가 있는지 짚고 넘어가도록 하겠다.
Causal Inference
정의: 원인과 결과 간의 인과 관계를 추론하려는 통계적 기법과 방법론
목적: 특정 처리 변수 또는 이벤트가 다른 변수에 미치는 인과적 영향을 추정
사용되는 방법: 다양한 통계적 모델링 기법이 사용되며, 실험적인 설계 (Randomized Controlled Trials, RCTs) 또는 관측적인 데이터에서의 처리 효과를 추론하는 방법이 포함됨
Causal Impact
정의: 특정 이벤트 또는 처리 변수의 발생이 시계열 데이터에 미치는 영향을 분석하기 위한 모델링 기법
목적: 특정 이벤트가 발생한 후의 시계열 데이터와 발생하기 전의 데이터를 비교, 이벤트 영향 정량화
사용되는 방법: BSTS 모델 기반, 사전/사후 비교를 통해 특정 이벤트의 영향 추정
Causal Inference는 원인과 결과 간의 일반적인 인과적 원리를 다루는 통계적 추론의 영역이며, Causal Impact는 특정 이벤트의 발생이 시계열 데이터에 미치는 영향을 분석하는 구체적인 모델링 기법이다. 본 포스트에서는 Causal Impact에 대해서 더 자세히 다뤄 볼 예정이다.
2. Bayesian structural time series (BSTS)
구조적 베이지안 시계열 방법으로 직역할 수 있다. 시계열 데이터를 '구조적 베이지안' 이라는 방법으로 분석한다고 해석할 수도 있다. 그렇다면 구조적 베이지안 방법이라는 것은 어떤 것일까?
시계열 분석에서 사용되는 통계적 접근 방식에는 크게 두 가지 방법이 존재한다.
빈도주의
얼마나 자주 특정 사건이 반복되어 발생하는지에 집중
확률을 장기적으로 발생하는 사건의 빈도로 봄
MLE (최대 우도 추정)를 사용하여 모델의 파라미터 추정. 주어진 데이터에서 발생 가능성이 가장 높은 모수 (Ex. 평균, 분산 등)를 선택하는 방식
가설 검정이 자주 사용됨. 시계열 데이터에서 특정 효과의 유의성 검정 또는 모델의 정확성 테스트하는 등의 목적으로 사용 가능
여러 번의 실험, 관찰을 통해 알게된 사건의 확률을 검정하므로 사건이 독립적, 반복적, 정규 분포형태일 때 사용하는 것이 좋음
대용량 데이터를 쉽게 처리할 수 있음
데이터가 부족하거나 불확실 할 경우, 실험 결과도 불확실함.
Ex. ARIMA
베이지안
확률은 사건 발생에 대한 믿음 또는 척도
불확실성을 확률적으로 표현
사전 분포를 이용하여 베이즈 정리를 이용하여 사후 분포를 계산
신뢰 구간이 아니라 신뢰 구간의 확률적 버전인 신용 구간을 제공하며, 예측 분포를 통해 미래 값의 불확실성을 평가할 수 있음.
과거에는 연산량이 많아서 구현이 어려웠으나, 컴퓨터 연산 능력이 발전됨에 따라 통계/머신러닝 분야에서 많이 사용됨.
Ex. Prophet, Causal Impact
이처럼 베이지안 방법론은 사전 분포를 이용하여 사후 분포를 계산한다는 점과 불확실성을 확률적으로 표현한다는 점에서 Causal Impact 방법론에 적절한 통계적 접근 방식이라고 할 수 있다. (특정 이벤트 발생 전후의 개입 효과가 목표이기 때문)
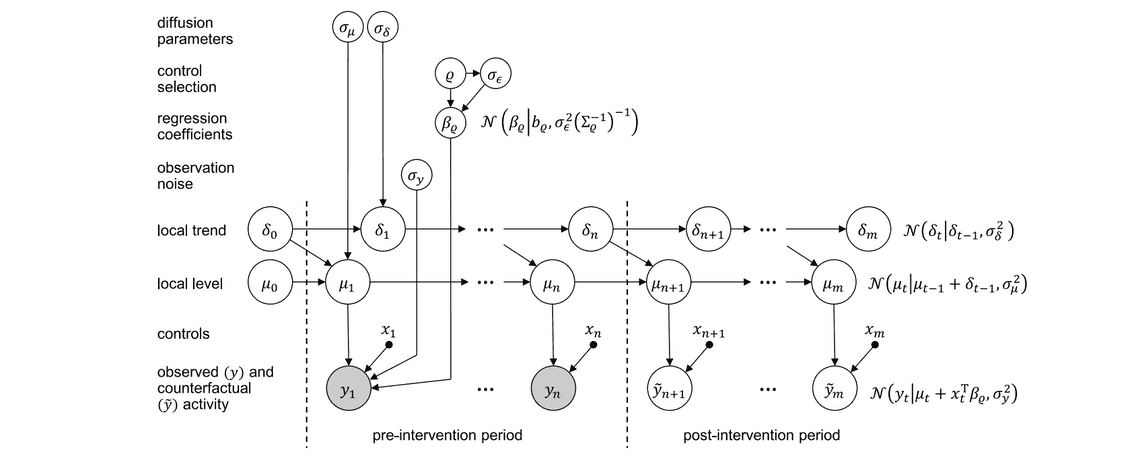
[그림 1] BSTS 구조
Causal Impact 내에서 사용되는 BSTS 모델의 내부 구조로는 크게 트렌드, 계절성, 회귀 모형이라는 3가지 상태 컴포넌트로 구성되어 있다.
트렌드: 장기적인 추세를 모델링
계절성: 주기적 패턴 학습 (시즌의 길이를 임의로 조정하여 학습 가능. Ex. 시즌 길이가 7일 경우, 일별 데이터에서 요일 효과를 얻을 수 있음)
회귀 모형: 모델링하려는 시계열 데이터에 영향을 미치는 외부 변수들과의 관계 정의. 외부 변수들을 활용하여 회귀 예측의 정확성을 향상시키는 역할
위의 컴포넌트로 모형을 구성하면 데이터를 통해 파라미터를 추론할 수 있으며, 파라미터 추론은 아래의 세 단계로 진행된다.
MCMC (Markov Chain Monte Carlo) 방식의 통계적 샘플링 알고리즘을 사용하여 특정 이벤트 개입 이전의 관측 데이터를 바탕으로 모형 파라미터와 상태 벡터를 시뮬레이션
개입 이전의 목표 시계열과 전체 기간의 공변량을 반영하여 개입이 없었을 경우의 시계열 분포 시뮬레이션
2번 단계에서 수행한 posterior 샘플링 결과를 통해 시점 별 인과 효과와 누적 인과 효과의 사후 분포 도출
파라미터 추론 후, 인과 효과를 개선하는 방식은 아래와 같이 활용할 수 있다.
이벤트 발생 시점 이후, 실제 시계열 데이터와 개입이 없을 경우 예측된 시계열 데이터 간의 시점 별 차이 (Impact) 도출
개입 이후 누적 효과 계산 (Ex. 누적 회원가입 수, 매출 등)
Causal Impact 모형의 가정 검증 방법
모형에 적용된 공변량의 개입 영향 파악. 예측값에 영향을 줄만한 변수들의 영향 파악 필요
이벤트 발생 또는 개입 시점 이전의 시계열 예측이 올바른지 확인 필요 (이벤트 발생 시점 이전의 예측 정확도)
이벤트 발생 또는 개입 시점 이후의 예측값 추이가 실제 값과 어떻게 차이가 나는지 비교 분석 (Ex. 회원 할인 쿠폰 발행 후, 쿠폰 발행 이벤트가 없었더라면 신규 회원 가입이 감소했을 것이라고 가정)
기존에는 의학 분야에서 환자들의 생존 가능성 추정에 많이 사용되었지만, 최근에는 제품 수명 예측, 고객 이탈률 등 다양한 분야에서도 많이 활용됨
<주요 키워드>
생존: 특정 사건이 아직 발생하지 않은 상태
시간 (Time): 상대적 시간을 의마함. 분석하려는 대상을 관찰하기 시작한 시점으로부터 경과한 시간
사건 (Event): 생존의 반대 상태. 사망, 고객 이탈 등 생존 분석을 하기 위한 대상이라고 해석. 생존 분석에서는 오로지 한 번만 발생 (사건 발생 or 발생하지 않음)
중도절단 (Censored): 관찰을 시작하기 전, 후로 나누어 해석 가능
Right Censored: 대상에 아직 사건이 발생하지 않거나, 기타 이유로 관찰이 종료된 것. 실제 생존 시간이 관찰 기간보다 긴 경우를 의미함
Left Censored: 대상을 관찰하기 전에 이미 사건이 발생 또는 기대한 최소 기간보다 생존 기간이 더 짧은 경우
생존함수 (Survival Function): 관찰 대상이 특정 시점보다 더 오래 생존 (사건이 발생하지 않을)할 확률을 계산하는 함수 (누적 생존 확률)
위험함수 (Hazard Function): 특정 시점에 사건이 발생할 확률. 이 때, 사건이 발생하기 전에는 해당 사건이 발생하면 안됨. 대상이 특정 시점까지 생존한 상태에서 특정 시점에 사건이 발생할 확률
누적위험함수 (Cumulative Hazard Function): 위험함수를 관찰을 시작한 시점부터 사건이 발생한 시점까지 적분한 값. 즉, 사건 발생 시점 전까지 관찰 대상에게 사건이 발생할 확률을 각각의 시점마다 구한 후, 모두 더한 것
2. 생존 분석 방법
2.1) Kaplan-Meier 추정
추정 방법: 관찰 시간에 따라 사건이 발생한 시점의 사건 발생률 계산, 시간에 따른 생존 함수를 추정
데이터를 시간에 따라 정렬
각 시점마다 생존해 있는 사람 수와 관찰 대상 그룹에 속한 사람 수 정리 (관찰 대상 그룹에는 관찰이 중단된 사람, 생존해 있는 사람, 사건이 일어난 사람 세 부류가 있다)
수식
S(t): 시간 t에서의 생존 확률
t(i): 이벤트가 발생한 시간의 집합
d(i): 시간 t(i)에서 이벤트가 발생한 개수
n(i): 시간 t(i)에서 생존 가능한 개체의 수
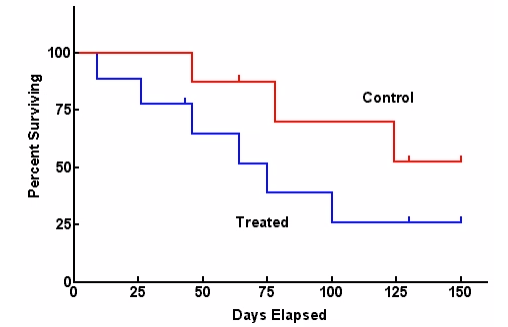
[그림 1] 두 그룹 간 캐플런 마이어 추정을 이용한 그래프
특징
이벤트가 발생하지 않는 시간까지 각 시간의 생존 확률 계산
이벤트가 발생한 시간에서의 생존 확률 S(t)는 해당 시간 직전까지의 누적확률에 현재 시간에서의 생존 확률을 곱한 것
사건이 발생하지 않은 관측치에 대해서도 누적 확률 도출 가능
다양한 시점에서 사건이 발생할 수 있는 경우에 유용함
두 그룹의 생존하는 비율 차이 비교에 사용됨 (실험군 vs 대조군 비교 시, 신뢰구간 비교)
비모수적 추정 방법
비모수적 통계방법: 확률 분포에 대한 가정을 하지 않고, 데이터의 분포나 특성에 대한 일반적인 추론을 수행하는 통계적 방법, 관측값의 순위 또는 분포를 사용하여 추론 수행, 특정한 가정 없이 데이터를 다룰 수 있음
모수적: 특정한 확률 분포를 기반으로 모집단의 특성을 추정
2.2) Log Rank Test
추정 방법: 생존 함수 분포를 비교하고 유의한 차이가 있는지 알아보는 가설 검정 기법
Kaplan-Meier 생존 곡선 [그림 1]을 사용하여 그룹 간의 생존 분포가 통계적으로 유의미한 차이가 있는지 확인
각 그룹에서 발생한 사건의 수와 관측치 수를 이용하여 기대되는 사건의 수와 실제로 발생한 사건의 수 간의 차이를 검정
Log Rank Test 수식
수식
예상 이벤트: 특정 시간에서 그룹 내 발생할 것으로 예상되는 사건의 수, 특정 시간에서의 생존 확률과 그 시간 간격을 곱하여 계산
실제 이벤트: 해당 시간에서 그룹 내에서 실제로 발생한 사건 수
2.3) Cox 비례 위험 모형 (Cox Proportional Hazard Model)
추정 방법
생존 시간에 영향을 미치는 요인들의 효과 추정
변수들 간의 비례적 위험 가정: 위험비(변수 한 단위가 변화할 때 변화하는 위험함수 값)가 생존 기간 내내 시간과 무관하게 일정하다고 가정
설명 변수들의 위험 비율이 시간에 따라 변하지 않고 일정하다고 가정 (단, 생존에는 영향을 주는 변수)
Hazard: 위험률, 어느 시점에 대상이 탈락가능성이 높은지 평가하는 비율
Cox 비례 위험 모형 기본 수식
수식
h(t): 시간 t에서의 위험 비율 (두 그룹 간의 위험의 상대적 크기)
h0(t): 기준 위험 비율
x1, x2, ..., xp: 독립 변수
beta1, beta2, ..., betap: 설명 변수의 회귀 계수
특징
Kaplan-Meier, Log-Rank Test와 달리, 설명 변수들의 함수 형태나 생존 곡선의 형태에 대한 가정을 하지 않음, 모델이 더 유연하게 다양한 데이터에 적용 가능
비례적 위험 가정
독립 변수 여러 개 고려 가능
Semi Parametric: 독립 변수 정보를 활용하지만, 생존 시간 분포 정보를 사용하지 않는 방법 (Kaplan-Meier 추정은 Non-Parametric, 독립변수와 생존 시간 분포 정보 모두 사용 안함, 분포 정보를 알 수 없을 때 유용하지만 예측이 부정확할 수 있음)